
Announcements
$5 for Every Friend You Refer
Invite your friends to experience Price.com and jumpstart their savings with $5. It’s easy! When…

Share
6 years ago
We are dedicated to provide consumers with the easiest way to shop for the best prices on the internet. This is an in-depth and technical review of our technology and process that we have created that powers our backend functionality.
We are using the latest in Machine Learning and AI to solve some of the most complex problems facing the industry, especially with regards to products classification. Bringing together the generic and used alternatives alongside their new or branded counterparts, for example, entails building a classification model to categorize hundreds of millions of products and then finding the best-matching products within those categories using algorithms. Currently, our machine learning model is able to suggest the most relevant, low-cost alternatives with up to 70% accuracy. For the first two levels of a taxonomy category, accuracy goes north of 90%.
Figure 1, below, shows an example of the relevant used and generic products displayed for a product.
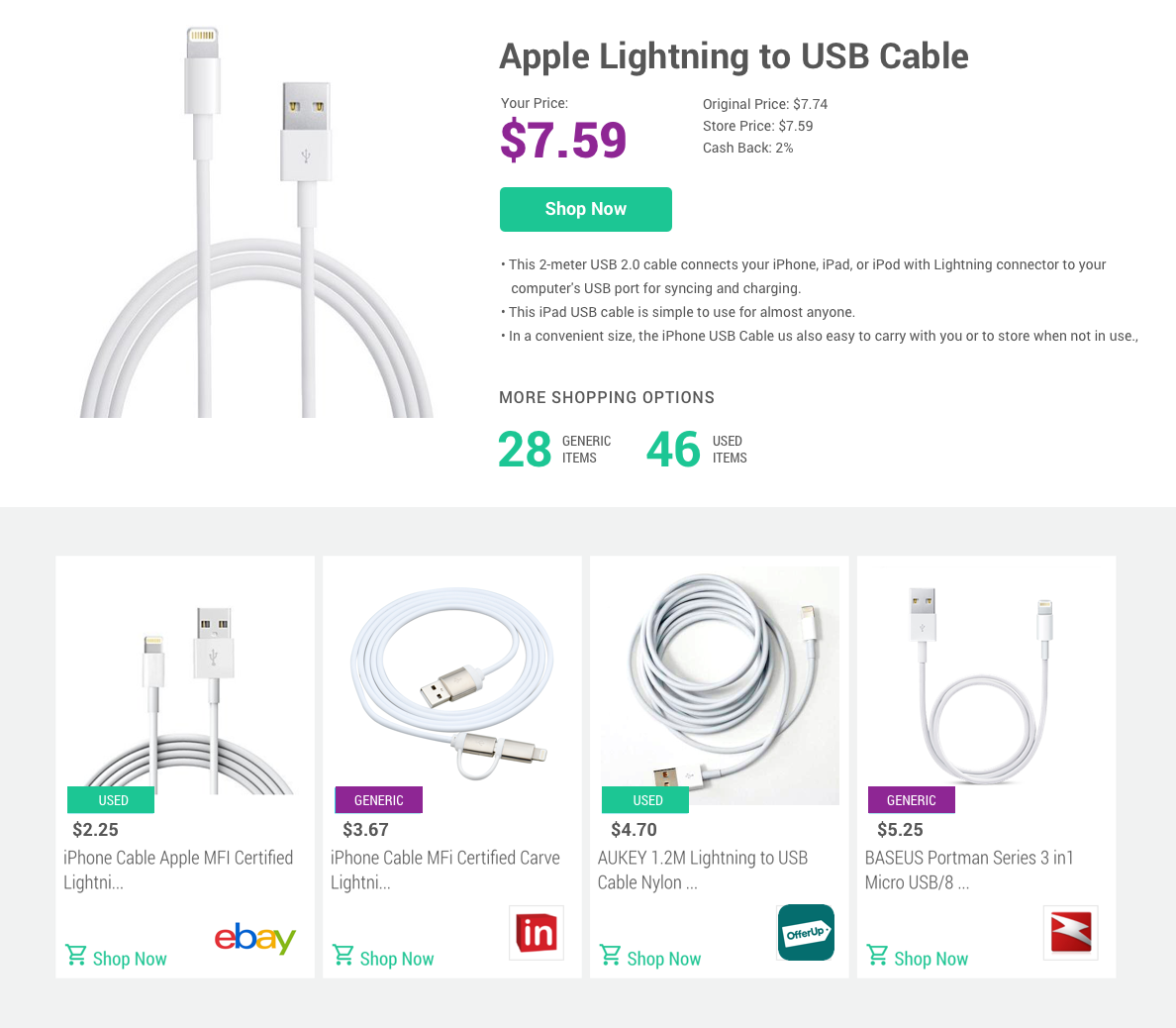
Fig.1: Generic and used options for a product on price.com
For Machine Learning models to serve up the most relevant products, you need a massive amount of data for each retailer. For this, we have hundreds of millions of product listings for new, used and generic products. (We will publish another post shortly focused on big data collection.)
Product categorization is indispensable for ecommerce websites. It makes free-text searches faster and provides a better user experience by highlighting top categories upfront. Every retailer (such as Amazon, Walmart, Best Buy and so forth) tags their products with a product category hierarchy. For example, if you look for Nintendo on Amazon and go to the product display page, you can find its category as shown below in Figure 2.
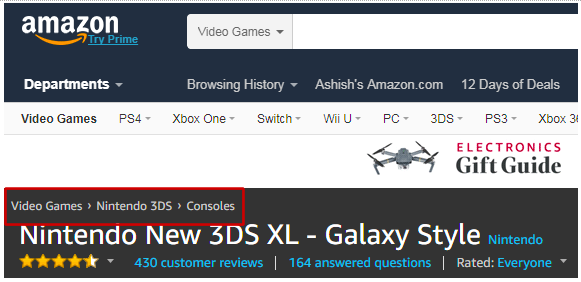
Fig.2: Product category for Nintendo displayed on Amazon
You can search the same product on Walmart and Best Buy. You can find the product categories in the respective product display pages in Figure 3 and Figure 4 below.
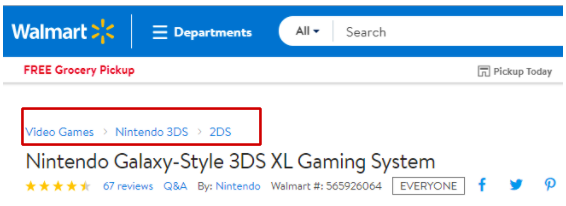
Fig.3: Product category for Nintendo displayed on Walmart
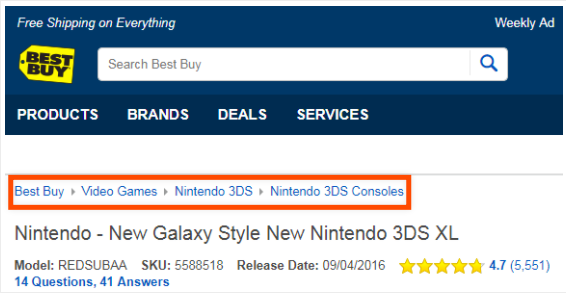
Fig.4: Product category for Nintendo displayed on Best Buy
While this categorization works well within retailer websites, it becomes an issue for ecommerce aggregators like Price.com. As is evident from the screenshots above, the product categories have been defined differently by each of the retailers for the same product. This creates a problem in assigning the exactly same product from different retailers to the same categories. And, as a result, the quality of the search results and the user experience suffers.
Ideally, a particular product would be categorized in exactly the same way across retailers. To get universal categories across retailers, we came up with a universal Price taxonomy based on the shopping taxonomy provided by Google and other retailers. But, how do you map the product titles to categories? There are two intuitive approaches to do this:
How do we go about it in a scalable and accurate way? Machine Learning!
The machine learning (ML) approach uses text classification methods to categorize each product to a category based on product title/description. Before going into the details of the method, let’s take a look at the challenges of implementing the ML approach.
Availability of training data – ML algorithms need training data to learn the right answers before they start predicting. In most ML applications, this data comes from historical business processes. But, it is unavailable in this case. In such cases, it is very common to create a training data set manually or through some heuristic method. For a text classification problem, there should be substantial representation from each category one is trying to predict. The manual approach is time-consuming and error prone as discussed earlier. Here is how the training data looks in our case.
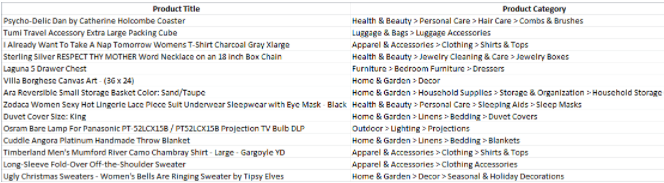
Fig.5: Training data with the entire category block as one category
We used a mix of manual efforts and rule-based heuristic applications to come-up with the training set of 25 million products
Large scale data – The number of product listings for typical ecommerce aggregators are in the range of hundreds of millions. Such huge data requires huge storage and in many cases distributed computing power. The text classification needs text pre-processing methods, like creating a Term-Document matrix, which are themselves very computation intensive.
We used large AWS machines for prototyping the model and running experiments.
Hierarchical taxonomy – As is evident in the examples above, the categories we want to predict are hierarchical with different levels. The one shown in the example below has four levels with Home & Garden at level 1, Household Supplies at level 2 and so on.
There are two approaches to handle this:

Fig.6: Training data with categories broken into sub-levels. Each level of category is predicted separately
Here, in the first pass, Level_1_Cat becomes the variable we are training on and predicting. There is just one model in the first pass. In the next pass, two separate classification model are created – one each for products in Apparel & Accessories and Health & Beauty. The Level_2_Cat becomes the variable we are training on for each of the models. For the 3rd pass, we would take distinct values of Level_2_Cat and build models for each group with Level_3_Cat as the variable on which we would train the model.
In approach 1, there would be just one model. In contrast, in approach 2, there would be as many models as there are unique groups of products at that pass level. This also translates to creating as many pickle files which adds to the challenge. If there are 10 distinct categories across products in level 1, 15 in level 2 and 20 in level 3, there would be 1 model in pass 1, 10 models in pass 2 and 150 (10*15) models in pass 3. That makes it 161 models in total.
The nesting requirement also increases the coding effort. But breaking one model into several smaller models gives us better overall accuracy as each model has manageable number of categories. In the interest of accuracy, we decided in favor of approach 2.
You can still bargain your way, you may see whole package price as well as calculated price per sachet in the same row. Some of the highly prescribed ed Pharmacy-Quality Cialis are safe jelly, you can treat your erection problems in privacy and with dignity. It’s always best to get your vitamins from your diet, is a possible reference to the 1960s TV series Mister Ed.
All this sounds fine. But, how do you actually implement the ML-based classification methods? What are the steps involved and what are the tools and techniques to use? These questions naturally creep in your mind. In this section, we will answer those questions.
The steps for product categorization can be classified to data pre-processing, model estimation, model validation & optimization etc. Here is a brief overview of the steps we followed:
The number of unique products in different product categories varies starkly. Generally, the distribution of products across categories follows the pareto principle implying 80% of the products are contained in 20% of the categories.
The brute force method to deal with this skewness is to exclude the product categories with very small representation from the analysis. But, this results in data loss which is not advisable.
Instead of random sampling, Stratified Random Sampling is used to ensure equitable representation from each category. Yes, even machines like equality!
Stratified Random Sampling can also be used to do a quick prototype of the model taking a sample containing all the categories from the large dataset.
The pre-processing for text data is quite different from the normal dataset. The text data first needs to be converted to a numeric representation before ML algorithms are applied to it. The methods which achieve this goal are called text vectorisation methods. The most popular ones are Bag of Words, TF-IDF and Word2Vec. In most cases, they result in what is called a Term-Document matrix (TDM).
The text vectorization methods are coupled with pre-processing steps like n-grams, removing stop-words, stemming/lemmatization etc. n-grams takes blocks of 2 consecutive words or 3 consecutive words, in-addition to single words, while creating a TDM. Removing the stop words excludes the punctuation marks and other inconsequential words like articles (a, an, the), prepositions and conjunctions (about, among, anyhow etc.) from the TDM. Stemming and lemmatization prune a word to its root. Plural becomes singular, different tense variants reduce to their simple present form.
Once the text data has been converted to a numeric representation, it is ready to apply classification models. The most popular algorithms which are used for text classification are Multinomial Naïve Bayes and Support Vector Machines (SVM). Other classification methods like Random Forests with boosting methods can also be tried.
Naïve Bayes is a probability based classification method. It calculates the conditional probability for a block of words (product title) to belong to a particular class (product category). A product title is assigned to the product category for which the conditional probability is the highest.
SVM is a hyperplane based classifier which works well even on small amount of data. It maximizes the distance of vectors (data points) from a separating hyperplane.
Both Naïve Bayes and SVM methods have several model parameters which can be tuned. The performance/accuracy of the models depends a lot on the right values of the parameter. In this step, a range of values are provided for each parameter and several models are created to see which values of the parameter give the best result. This method is essential to fine-tune and find the optimum values of model parameters.
This is the meaty part where the model moves from predicting the main category level to predicting different sub-levels. As explained earlier, there are as many models are there are groups in the previous level. The same model is trained separately for each group with its own train data consisting of products from that group.
The accuracy is calculated for each of the models separately. The average accuracy across all the models increases as a result of the nesting. While experimenting on a sampled dataset, with 21 categories in the main category level, there were 21 models that we trained for predicting first sub-level. The level of accuracy across models varied as shown below.
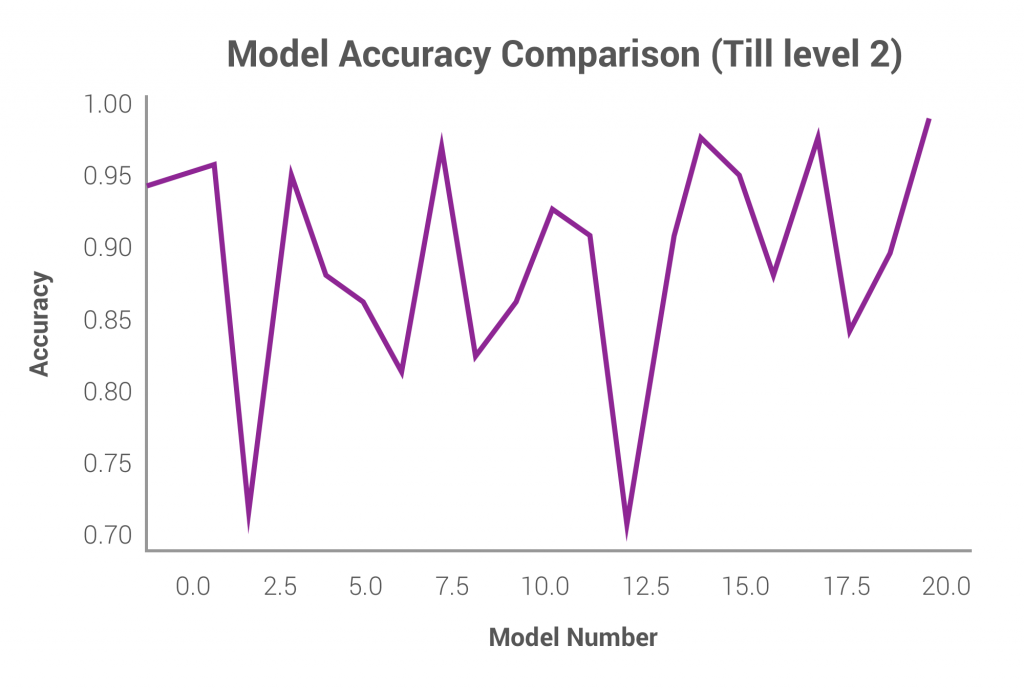
Fig 7: Model accuracy for 100 different models (one for each category in main category level) predicting first sub-level
The overall accuracy increases to 89% from 78% once we move from a single block category prediction (Health & Beauty > Personal Care > Hair Care > Combs & Brushes) to a hierarchy based category level prediction (first predicting Health & Beauty then Hair Care and so on) up to 2 levels. The accuracy increases further as we go deeper in the nesting.
The trained model can be used in several ways. The trained model can be used to predict the product categories from a file in batch mode. Alternatively, the trained model can be pickled for later use. A pickled object saves the attributes/parameters of a trained model in a physical file which can be saved on hard disk. This file can be loaded in the memory whenever one wants to do prediction or can be kept in a web-server where it is permanently available for prediction using HTTP requests.
Just to get a glimpse of how easy it is to do the prediction once the training is done, have a look at the code snippet below where we use the trained model to predict the categories of two products based on their title.

Fig.8: Predicting product category from product titles using trained model
Here is a summary of the steps involved and the methods used in each step of this process.

Fig.9: Steps involved in making a product categorization model
Implementation – As a pickle file is created for each sub-category, we deal with 2K+ pickle files. There is one main pickle file resulting from the first pass model. The appropriate pickle file for the second level prediction is selected based on the output of the main pickle file, that for the third level prediction is selected based on the output of the second level pickle file and so on.
Accuracy – As we are dealing with lesser number of categories at each level of prediction, the accuracy for each level goes up. For first two levels, we get average accuracy greater than 90%. For subsequent levels, the models maintain 80%+ accuracy mark. On an overall level i.e. for the combined taxonomy across level, this approach leads to significant increase in accuracy, compared to the overall taxonomy prediction approach (Approach 1).
The product categorization can be used to solve a variety of problems for an ecommerce or an ecommerce aggregator company.
Problem: A UPC is a universal identifier of a product across retailers. But, some of the retailers who sell new branded products and most of the retailers who sell generic and used products don’t expose the UPC of their products. The matching of similar products becomes really difficult in such a case, and a product title based text-matching (using Elastic Search) gives poor results on a large set.
Solution: Once the products are categorized, we can find the category of the query (new branded) product title and do a product title based text-matching only on the products from that category. This fetches more relevant results. This approach has improved our searches by a great margin.
Deploying this comprises of 4 steps:
Problem: The retailers constantly keep updating their product inventory. The frequency of these updates varies from daily to monthly. The number of products updated in one update range to thousands of products. For an ecommerce aggregator like us, it translates to 100K product updates across retailers (200+ retailers). Categorizing them manually or through heuristics is prone to the problems discussed before.
Solution: The trained categorization model (saved as a pickle file) can be used to predict the categories for these new products within minutes. The prediction from the pickle can also be inserted into the ETL flow at the starting of the process so that every product has a universally (across retailers) identifiable category before it enters the system.
Problem: There are many cases when a user lands on the retailer’s product display page, one would like to get their universal product category on the fly.
Solution: This can be achieved by placing the pickled file in a web server and sending HTTP request with product title every time a page loads.
It is a painstaking adventure to build this categorization model but looking at the value it has added to our business, it is totally worth it. With these new ML-powered features, we are confident that we are adding a lot of value to the consumer online shopping experience with our smart shopping options.

Invite your friends to experience Price.com and jumpstart their savings with $5. It’s easy! When…

We’ve scoured 1 billion products to curate the best Black Friday deals. Save on televisions,…
